FAQs on: General

Sometimes, small things matter in big ways. e.g., all other things being equal, a job may be offered to the candidate who has the neater looking CV although both have the same qualifications. This may be unfair, but that's how the world works. Students forget this harsh reality when they are in the protected environment of the school and tend to get sloppy with their work habits. That is why we reward all positive behavior, even small ones (e.g., following precise submission instructions, arriving on time etc.).
But unlike the real world, we are forgiving. That is why you can still earn full marks for participation even if you miss a few things here and there.
Defining your own unique project is more fun.
But, wider scope → more diverse projects → harder for us to go deep into your project. The collective know-how we (i.e., students and the teaching team) have built up about SE issues related to the project become shallow and stretched too thinly. It also affects fairness of grading.

That is why a strictly-defined project is more suitable for a first course in SE that focuses on nuts-and-bolts of SE. After learning those fundamentals, in higher level project courses you can focus more on the creative side of software projects without being dragged down by nuts-and-bolts SE issues (because you already know how to deal with them). However, we would like to allow some room for creativity too. That is why we let you build products that are slight variations of a given theme.
Also note: The freedom to do 'anything' is not a necessary condition for creativity. Do not mistake being different for being creative. In fact, the more constrained you are, the more you need creativity to stand out.
We have chosen a basic set of tools after considering ease of learning, availability, typical-ness, popularity, migration path to other tools, etc. There are many reasons for limiting your choices:
Pedagogical reasons:
- Sometimes 'good enough', not necessarily the best, tools are a better fit for beginners: Most bleeding edge, most specialized, or most sophisticated tools are not suitable for a beginner course. After mastering our toolset, you will find it easy to upgrade to such high-end tools by yourself. We do expect you to eventually (after this course) migrate to better tools and, having learned more than one tool, to attain a more general understanding about a family of tools.
- We want you to learn to thrive under given conditions: As a professional Software Engineer, you must learn to be productive in any given tool environment, rather than insist on using your preferred tools. It is usually in small companies doing less important work that you get to chose your own toolset. Bigger companies working on mature products often impose some choices on developers, such as the project management tool, code repository, IDE, language etc. For example, Google used SVN as their revision control software until very recently, long after SVN fell out of popularity among developers. Sometimes this is due to cost reasons (tool licensing cost), and sometimes due to legacy reasons (because the tool is already entrenched in their codebase). While programming in school is often a solo sport, programming in the industry is a team sport. As we are training you to become professional software engineers, it is important to get over the psychological hurdle of needing to satisfy individual preferences and get used to making the best of a given environment.
Practical reasons:
- Some of the topics are tightly coupled to tools. Allowing more tools means tutors need to learn more tools, which increases their workload.
- We provide learning resources for tools. e.g. 'Git guides'. Allowing more tools means we need to produce more resources.
- When all students use the same tool, the collective expertise of the tool is more, increasing the opportunities for you to learn from each others.
Meanwhile, feel free to share with peers your experience of using other tools.
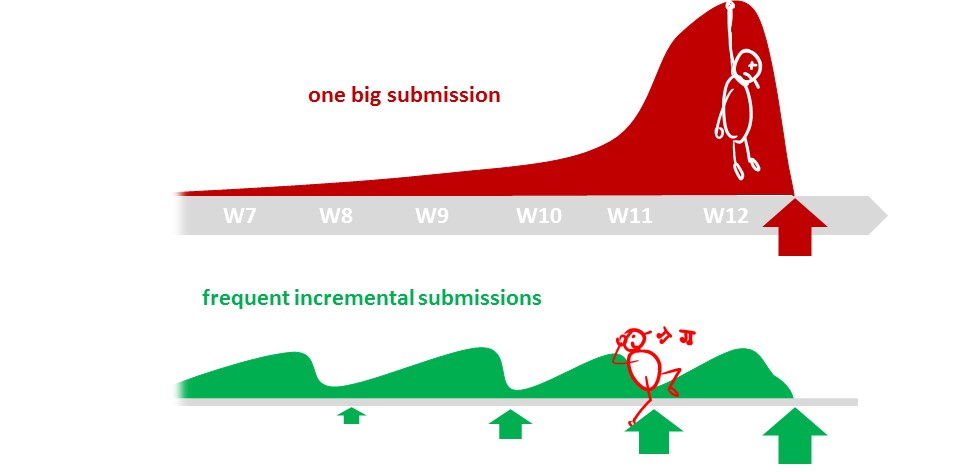
The high number of submissions is not meant to increase workload but to spread it across the semester. Learning theory and applying them should be done in parallel to maximize the learning effect. That can happen only if we spread theory and 'application of theory' (i.e., project work) evenly across the semester.
In addition, spreading the work across the semester aligns with the technique that we apply in this course to increase your retention of concepts learned.